














 incontournables en février 2026 : Le guide ultime")










Comprendre les codes de statut HTTP : le langage invisible du web
Chaque fois que vous naviguez sur internet, un dialogue silencieux s’établit entre votre navigateur et les serveurs web. Les codes de statut HTTP représentent ce langage technique qui détermine si une page s’affiche correctement, si elle a été déplacée ou si une erreur s’est produite. Ces nombres à trois chiffres constituent le système de communication fondamental du web moderne.
Imaginez ces codes comme des réponses standardisées que les serveurs envoient à chaque requête. Quand vous cliquez sur un lien ou tapez une URL, votre navigateur envoie une demande au serveur, qui répond immédiatement avec un code spécifique. Ce mécanisme reste invisible pour la majorité des utilisateurs, mais son importance est capitale pour le bon fonctionnement des sites web.
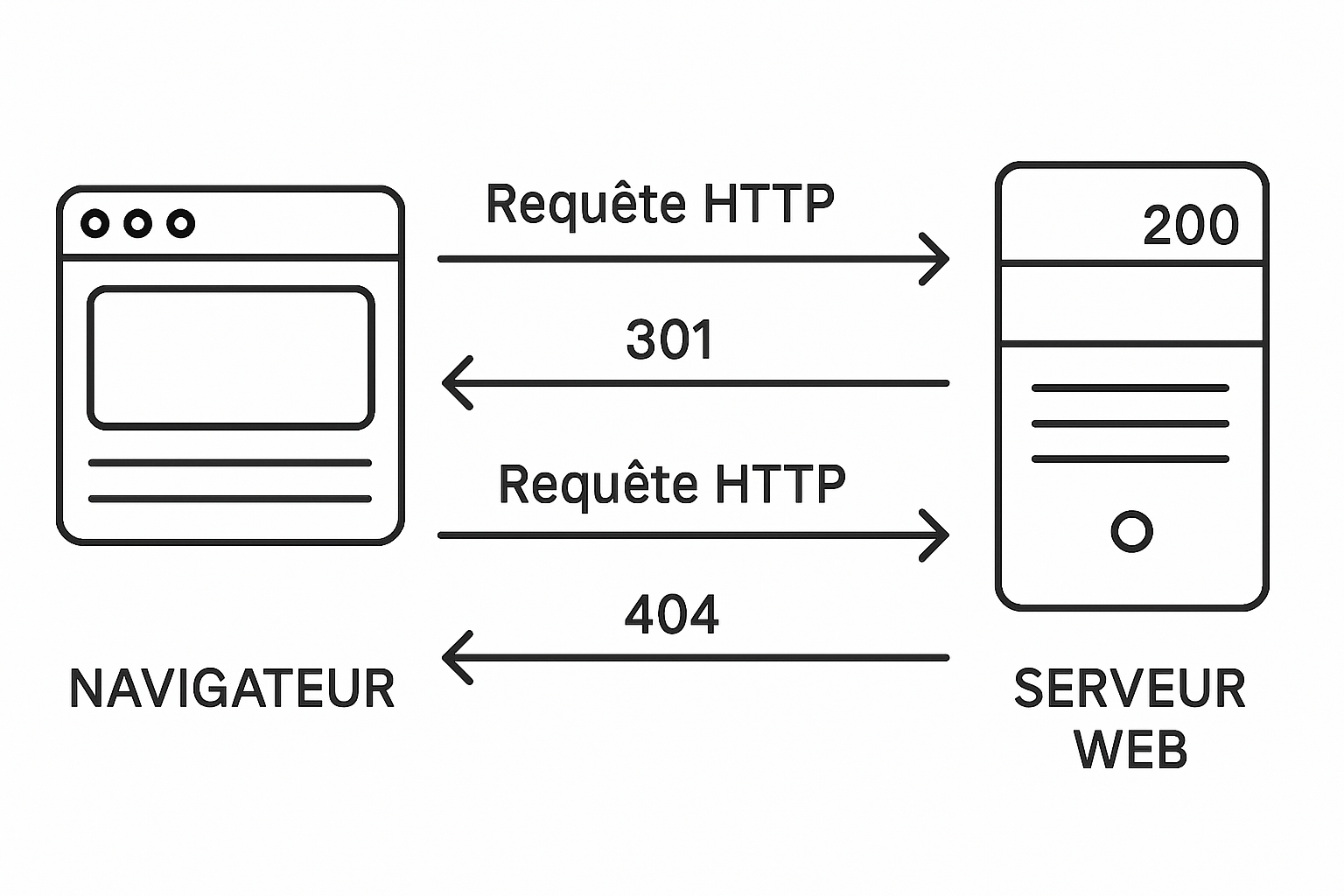
La structure logique des codes HTTP
Les codes de statut suivent une organisation méthodique basée sur leur premier chiffre :
- 1xx – Codes informationnels : Le serveur a reçu la requête et continue le traitement
- 2xx – Codes de succès : L’opération s’est déroulée sans problème
- 3xx – Codes de redirection : La ressource demandée a changé d’emplacement
- 4xx – Erreurs client : La requête contient une erreur ou ne peut être traitée
- 5xx – Erreurs serveur : Le serveur rencontre des difficultés internes
Cette classification permet aux développeurs et aux outils d’analyse de comprendre rapidement la nature d’un problème. Par exemple, un code commençant par 4 indique généralement une erreur côté client, tandis qu’un code débutant par 5 signale un dysfonctionnement serveur.
Les codes informationnels 1xx : la préparation en coulisses
Les codes 1xx fonctionnent comme des messages d’état temporaires durant le traitement des requêtes. Ils informent le client que le processus est en cours et lui indiquent comment procéder. Bien que rarement visibles par les utilisateurs finaux, ces codes jouent un rôle crucial dans les communications complexes.
| Code | Nom | Signification | Utilisation typique |
|---|---|---|---|
| 100 | Continue | Le serveur accepte les en-têtes de requête | Uploads de fichiers volumineux |
| 101 | Switching Protocols | Changement de protocole accepté | Passage de HTTP à WebSocket |
| 102 | Processing | Requête en cours de traitement | Opérations WebDAV longues |
Le code 100 Continue est particulièrement important pour les transferts de données conséquents. Il permet au client d’envoyer le corps de la requête après avoir vérifié que le serveur peut le traiter. Cette approche évite les transferts inutiles lorsque le serveur rejette la requête basée sur les en-têtes.
Le 101 Switching Protocols intervient lorsque le client demande un changement de protocole, comme lors de l’établissement d’une connexion WebSocket pour des applications temps réel. Le serveur accepte alors de modifier le mode de communication pour la suite des échanges.
Les codes de succès 2xx : quand tout fonctionne parfaitement
Les codes 2xx représentent le scénario idéal : la requête a été reçue, comprise et traitée avec succès. Ces codes confirment que l’opération demandée s’est déroulée comme prévu, sans erreur ni complication.
Le 200 OK est sans conteste le code le plus connu et le plus souhaitable. Il indique que la requête a abouti et que la réponse contient les données demandées. Quand une page web s’affiche correctement, c’est généralement grâce à ce code.
- 201 Created : Une nouvelle ressource a été créée suite à une requête POST ou PUT
- 202 Accepted : La requête a été acceptée mais le traitement n’est pas terminé
- 204 No Content : Succès mais pas de contenu à retourner
- 206 Partial Content : Le serveur renvoie une partie des données demandées
Le code 201 Created est fréquemment utilisé dans les API REST après la création réussie d’une ressource. Il est souvent accompagné d’un en-tête Location indiquant l’URL de la nouvelle ressource. Cette approche standardisée facilite l’intégration entre systèmes.
Le 204 No Content trouve son utilité dans les opérations de suppression ou de mise à jour où aucun contenu supplémentaire n’est nécessaire. Par exemple, lorsqu’un utilisateur supprime un élément via une interface, le serveur peut répondre avec ce code pour indiquer le succès de l’opération sans renvoyer de données.
Les codes de redirection 3xx : gérer les changements d’adresse
Les redirections sont essentielles pour maintenir la continuité de l’expérience utilisateur lorsque le contchange d’emplacement. Les codes 3xx indiquent au client que des actions supplémentaires sont nécessaires pour compléter la requête.
| Code | Nom | Impact SEO | Utilisation recommandée |
|---|---|---|---|
| 301 | Moved Permanently | Transfert complet de l’autorité | Changements définitifs d’URL |
| 302 | Found | Aucun transfert d’autorité | Redirections temporaires |
| 304 | Not Modified | Optimisation des performances | Utilisation du cache navigateur |
| 308 | Permanent Redirect | Transfert complet d’autorité | Redirections permanentes modernes |
La redirection 301 Moved Permanently est cruciale pour le référencement. Quand vous modifiez définitivement l’URL d’une page, ce code transfère environ 90-99% de l’autorité SEO vers la nouvelle adresse. Les moteurs de recherche mettent alors à jour leurs index en conséquence.
Le code 304 Not Modified optimise les performances en permettant aux navigateurs d’utiliser leurs versions en cache. Quand un serveur renvoie ce code, il indique que la ressource n’a pas changé depuis la dernière requête, évitant ainsi un téléchargement inutile.
Il est essentiel d’éviter les chaînes de redirections (A → B → C) qui ralentissent le chargement et diluent l’autorité SEO. Pour des résultats optimaux, redirigez toujours directement vers la destination finale. Comme le montrent plusieurs analyses de performance des services web, les redirections directes améliorent significativement l’expérience utilisateur.
Les erreurs client 4xx : quand le problème vient de la requête
Les codes 4xx indiquent que la requête contient une erreur empêchant son traitement. Le serveur a compris la demande mais ne peut l’exécuter à cause d’un problème côté client. Ces erreurs sont parmi les plus fréquemment rencontrées par les utilisateurs.
L’erreur 404 Not Found est certainement la plus célèbre du web. Elle se produit lorsque la ressource demandée n’existe pas à l’URL spécifiée. Cela peut arriver suite à la suppression d’une page, une URL mal orthographiée ou un lien cassé. Une gestion proactive des liens permet de réduire considérablement ces occurrences.
- 400 Bad Request : La requête est malformée ou syntaxiquement incorrecte
- 401 Unauthorized : Authentification requise pour accéder à la ressource
- 403 Forbidden : Accès refusé malgré une authentification valide
- 404 Not Found : La ressource demandée est introuvable
- 429 Too Many Requests : Limite de requêtes dépassée
L’erreur 403 Forbidden diffère du 401 en ce qu’elle se produit même lorsque l’utilisateur est authentifié. Cela indique que le serveur comprend la requête mais refuse de l’autoriser en raison de permissions insuffisantes. Comme le démontrent certaines configurations de sécurité avancées, une gestion fine des permissions est essentielle.
Le code 429 Too Many Requests protège les serveurs contre les attaques par déni de service et le spam. Il indique que l’utilisateur a envoyé trop de requêtes dans un intervalle de temps donné. Les API modernes utilisent ce mécanisme pour préserver leurs ressources et assurer un service équitable à tous les utilisateurs.
Les erreurs serveur 5xx : quand le problème est interne
Les codes 5xx signalent que le serveur a rencontré une situation l’empêchant de satisfaire une requête valide. Contrairement aux erreurs 4xx, la responsabilité incombe ici au serveur, non au client. Ces erreurs nécessitent une intervention technique immédiate.
L’erreur 500 Internal Server Error est un code générique indiquant qu’une condition inattendue s’est produite. Le serveur ne peut fournir plus de détails sur la nature exacte du problème. Comme l’ont montré plusieurs incidents techniques majeurs, une surveillance proactive est essentielle pour détecter rapidement ces problèmes.
| Code | Nom | Cause probable | Action corrective |
|---|---|---|---|
| 500 | Internal Server Error | Erreur de script ou configuration | Vérifier les logs d’erreurs |
| 502 | Bad Gateway | Réponse invalide d’un serveur amont | Vérifier les services backend |
| 503 | Service Unavailable | Serveur en maintenance ou surchargé | Surveiller la charge serveur |
| 504 | Gateway Timeout | Timeout d’un serveur amont | Optimiser les timeouts |
Le code 503 Service Unavailable indique que le serveur est temporairement incapable de traiter les requêtes. Cette situation peut survenir pendant les opérations de maintenance, les pics de trafic ou les problèmes de capacité. Une page de maintenance bien conçue, comme celles évoquées dans certaines documentations techniques, peut améliorer l’expérience utilisateur durant ces périodes.
L’erreur 502 Bad Gateway se produit lorsque le serveur, agissant comme passerelle, reçoit une réponse invalide d’un serveur en amont. Cela peut indiquer des problèmes de connectivité réseau, des services backend indisponibles ou des configurations incorrectes de proxy.
Impact SEO et bonnes pratiques d’optimisation
Les codes de statut HTTP influencent directement votre référencement naturel et l’expérience utilisateur. Une gestion appropriée peut significativement améliorer votre visibilité dans les moteurs de recherche, tandis que des erreurs répétées peuvent nuire à votre classement.
Les moteurs de recherche interprètent les codes de statut pour évaluer la santé et la pertinence de votre site. Comme le soulignent plusieurs analyses sectorielles, la qualité technique devient un facteur de différenciation croissant dans les résultats de recherche.
- Codes 2xx : Excellents pour le SEO, les pages sont indexées normalement
- Codes 301/308 : Transfèrent l’autorité SEO vers les nouvelles URLs
- Codes 404 : Peuvent nuire au référencement si trop nombreux
- Codes 5xx : Très négatifs, peuvent entraîner une désindexation
La surveillance régulière des codes de statut est essentielle pour maintenir un site performant. Des outils comme Google Search Console, Screaming Frog SEO Spider ou des services de monitoring automatique permettent de détecter rapidement les problèmes émergents. Comme le démontrent certaines stratégies de monitoring avancées, une approche proactive permet de résoudre les problèmes avant qu’ils n’affectent les utilisateurs.
L’optimisation des performances passe également par une gestion intelligente du cache et des redirections. Évitez les chaînes de redirections multiples qui ralentissent le chargement et configurez correctement les en-têtes de cache pour les ressources statiques. Ces bonnes pratiques, combinées à une surveillance continue, constituent la base d’une présence web robuste et performante.






